电商搜索数据同步方案
前言
搜索系统主要分为两个部分一个是在线服务、一个是离线服务,在线服务是指排序、打分等靠近用户侧的部分,离线服务负责这篇文章属于离线部分范畴,本篇文章只是提供一个基础的思路,实际使用还需要适当调整和拓展。无论哪种方式都应该保证全量高吞吐、增量低延时的这个原则。
方案
定时任务主动拉取更新
这个方案是最简单最直观的实现方式,通过 SQL 关联查询,全量更新和增量更新通过定时任务去触发。
优点:适合快速开发,且与业务系统代码解耦。
缺点:对数据库压力较大;如果跨数据库关联会增加复杂度;实时性低。
订阅队列异步更新
异步更新常出现在事件驱动的架构中,扣件库存事件、价格变更事件、商品上下架事件等,这种方案需要分布式队列的支持。
优点:实时性高,对数据库压力小。
缺点:需要保证消息的消息队列的可靠性、顺序消费、重复消费等;对非事件驱动架构的业务代码有入侵性。
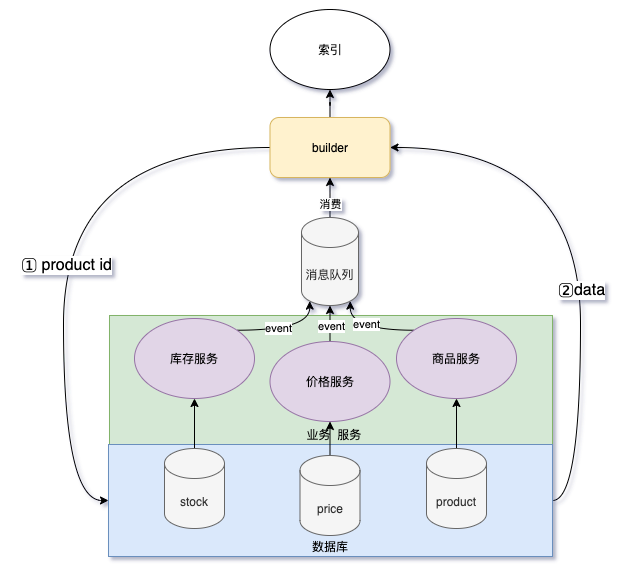
说明:上图中 product id 是从消息队列拿到变更的商品 id,然后根据 id 去反查业务库中的数据;data 是通过 SQL 拿到的结构化数据,这个步骤在全量更新时也会用到。
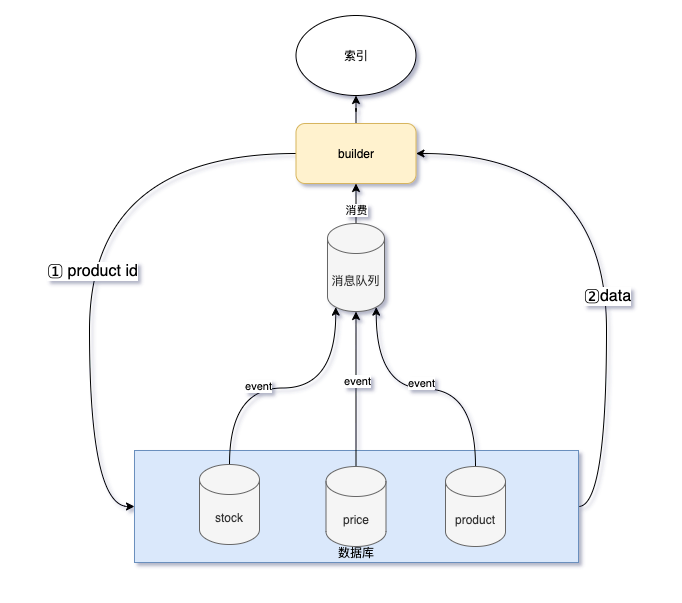
使用 Binlog 工具更新
Binlog 是 MysQL 中最重要的日志,它记录了 DDL 和 DML 操作,在 MySQL 主从复制或者数据恢复时会使用到,当然也可以用在同步数据上,由于 Binlog 是二进制文件无法直接使用,市面上有很多成熟的解析工具,目前 Canal 是比较适合国内的业务场景。
优点:与业务系统解耦
缺点:需要引入消息队列和 Binlog 解析中间件,增加了架构的复杂性
总结
上面介绍了搜索的三种数据同步方案,使用者需要根据实际的业务场景进行选择和拓展。
监听 Binlog 这种设计在搜索系统中的使用场景仅限于数据的增量同步,这样能够做到准实时更新,而对于同步更新则需要进行周期性的通过 SQL 或者接口进行更新。
参考链接
https://insights.thoughtworks.cn/application-of-cdc-in-microservices/
- 原文作者:浮华生
- 原文链接:https://www.ahianzhang.com/post/change-data-capture/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。