ElasticSearch 基础概念
documnet
文档,类似于 Java 的实体类,但非面向对象的,比实体类更加灵活。
index
索引,用来存放文档,一个索引可存放若干个 document
type
ElastcSearch 7 以后过时,使用 _doc 代替,预计在未来会移除
node
单个服务器,其实就是一个 ES 实例,多个 node 组成一个集群,node 能够进行索引和查询操作。默认每个 node 启动时会分配一个 UUID 作为标识。
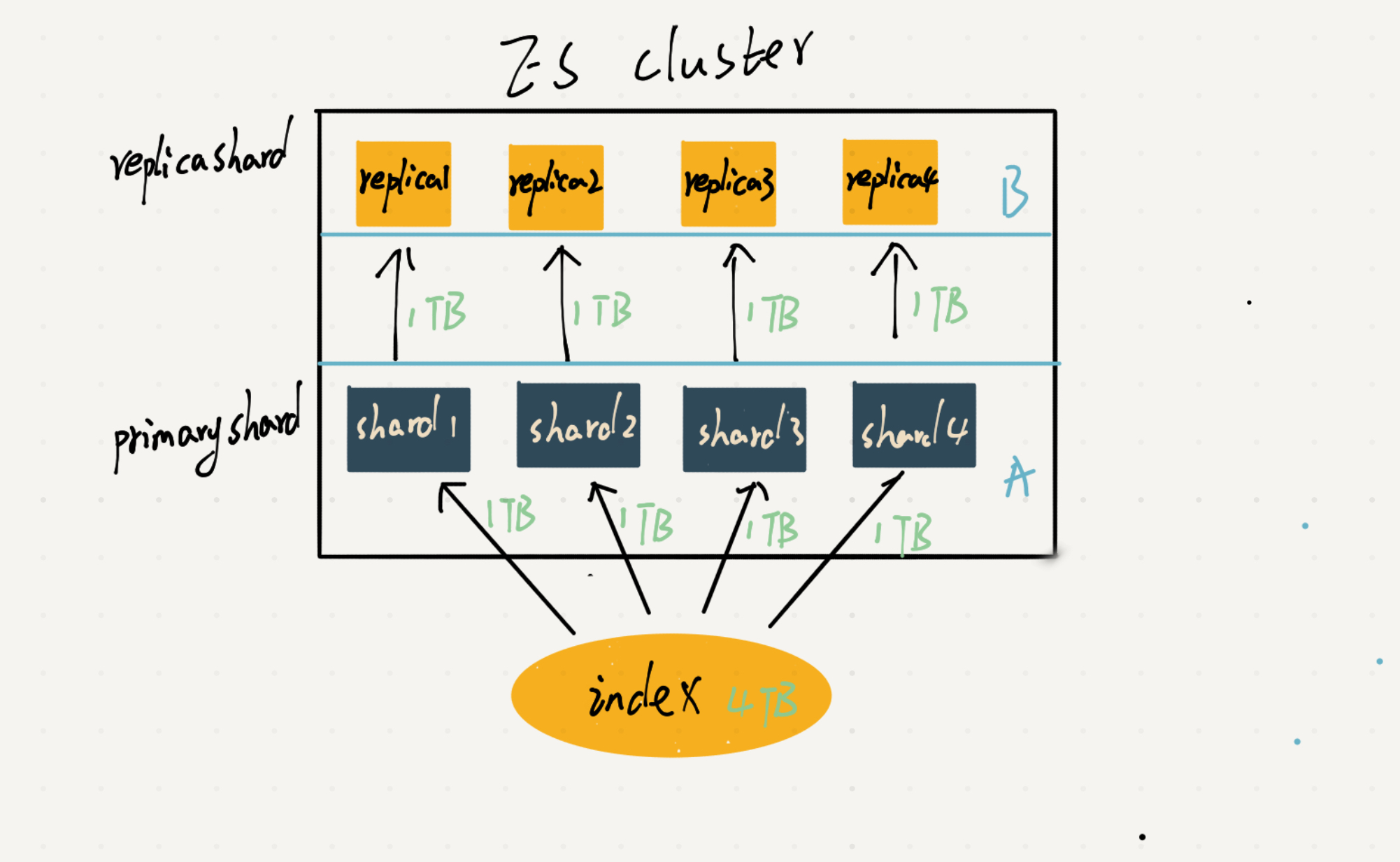
shard
分片,用来存储索引,分为以下两个shard,平时认为 shard 为 primary shard 。
ES 默认会分配 一个 primary shard 和与之对应的 replica shard。
分片的目的是对 index 进行横向拆分,避免 index 容量过大所带来的性能和系统稳定问题,以及它的 failover mechanism 能够增加几群的容错能力。
引用官方的话
Sharding is important for two primary reasons:
- It allows you to horizontally split/scale your content volume
- It allows you to distribute and parallelize operations across shards (potentially on multiple nodes) thus increasing performance/throughput
对于 shard 它是有容量上限的(Integer.MAX_VALUE - 128)
Each Elasticsearch shard is a Lucene index. There is a maximum number of documents you can have in a single Lucene index. As of
LUCENE-5843, the limit is2,147,483,519(= Integer.MAX_VALUE - 128) documents. You can monitor shard sizes using the_cat/shardsAPI.
primary/original shard
主分片
replica shard
副本分片,是主分片的副本,其内容和主分片内容一致,但不会同自己的主分片放在同一个 node 上。
cluster state
集群状态
| 颜色 | 说明 |
|---|---|
| green | 集群健康 |
| yellow | 有 replica shard 没有正常运行 |
| red | 有 primary shard 没有正常运行 |
参考文章:
https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started-concepts.html
- 原文作者:浮华生
- 原文链接:https://www.ahianzhang.com/post/elastic-search/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。