RabbitMQ 和 Kafka 应用原理简单对比
在实际工作中用到了 RabbitMQ 和 Kafka,本篇文章围绕二者在使用上的一些认知进行展开,不涉及技术细节,仅做实践上的参考。
RabbitMQ
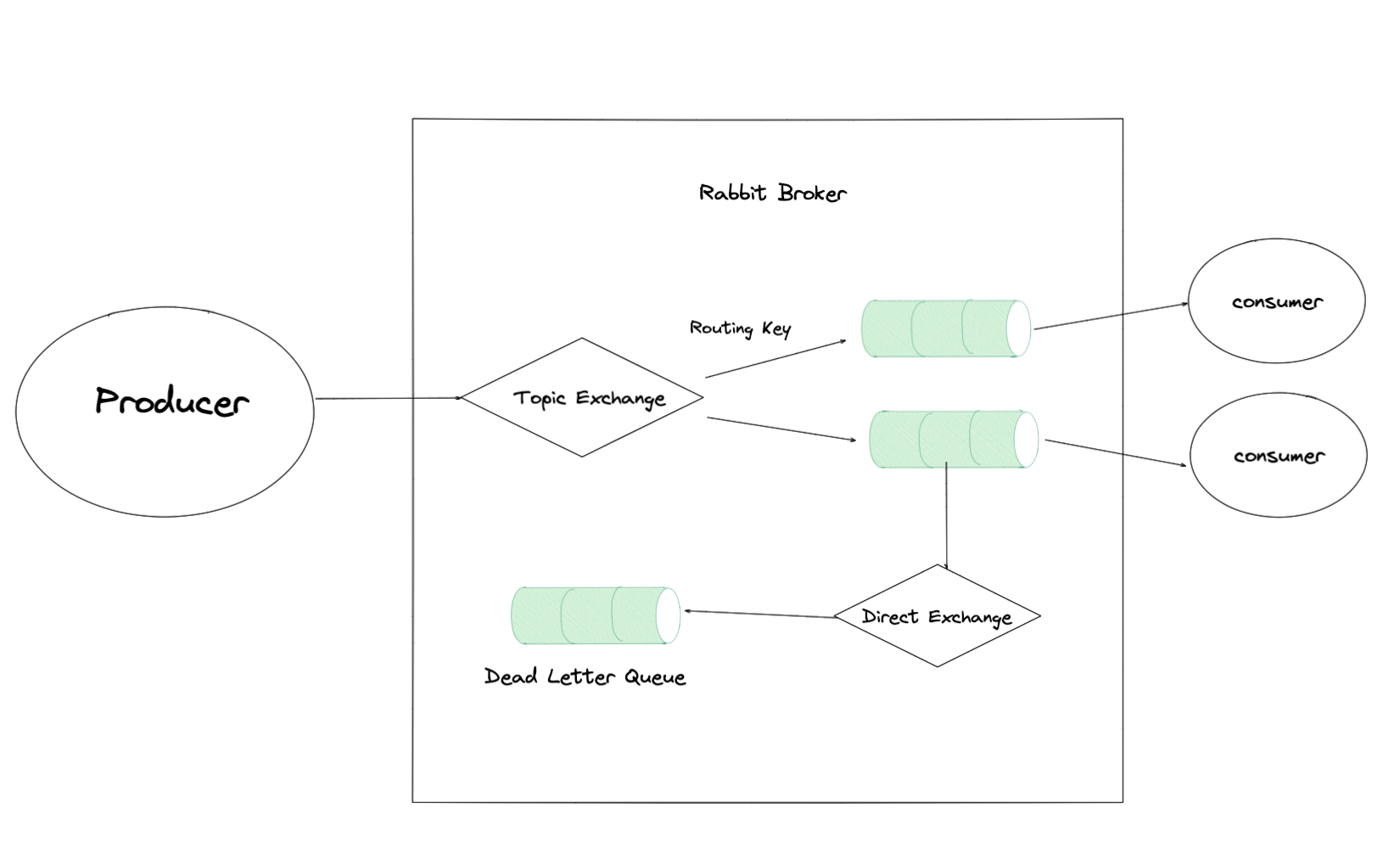
多用于处理业务系统之间的信息交互,所以需要保证消息的可靠性和幂等性,我在项目中实际使用的是 at-least-once 投递方式,然后针对每条消息做幂等处理。
在使用 Spring Boot AMQP 或者其他 Rabbit clien开发时,一般不会直接通过代码的方式创建队列和交换机等资源,而是由运维在控制台创建好,然后在项目中配置这些信息,修改和删除时也是同理。私信队列是为了消息达到重试最大次数后能够查看或者做其他业务操作。
一个 Queue 对应一个消费者,如果一个消费者有多个节点则会进行轮询发送。
Kafka
Kafka多用于数据处理方面。一个 Broker 中可以有多个 Topic,每个 Topic 下又可以有多个 Partition,Kafka 保证是每个 Partition 内部有序。在消费消息时监听 Topic,此时接收到的数据并非是严格有序的,要想做到有序最简单的方式就是一个 Topic 只有一个 Partition。同一个消费组内,消息只会被一个消费者消费;如果两个不同的消费组内监听同一个 Topic 消息,那么这些消息会被这两个消费组内的某个消费者消费。
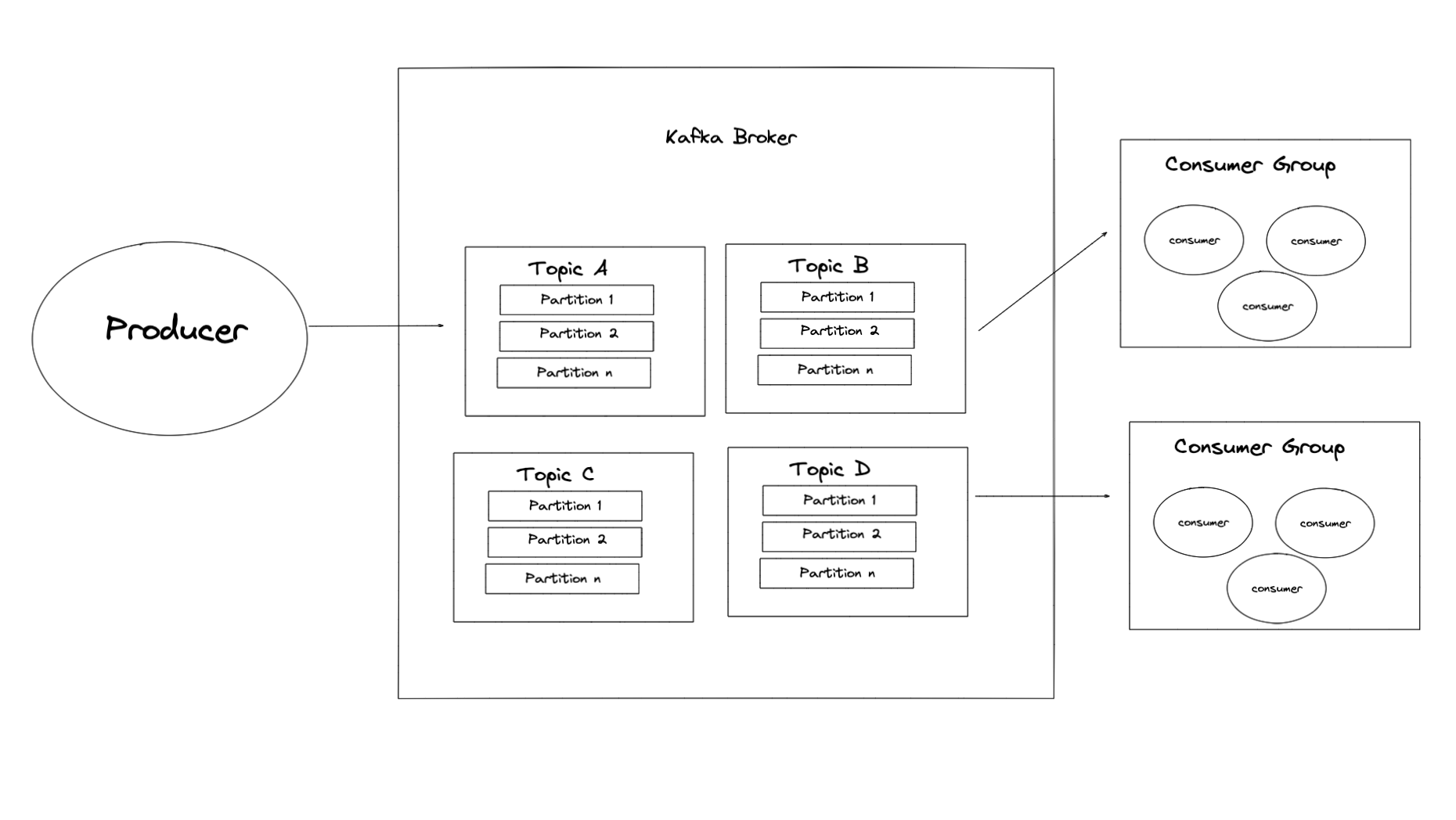
Kafka 实现类似 RabbitMQ 的 Topic 功能
- 原文作者:浮华生
- 原文链接:https://www.ahianzhang.com/post/message-queue/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。