阿里云 OpenSearch 介绍
阿里云 OpenSearch 是一款基于 Ha3 引擎研发的商用搜索产品。在使用上给我的个人感受可以说 OpenSearch 是一套企业级搜索的完整解决方案的落地。下面我们来看一下 OpenSearch 有哪些功能。
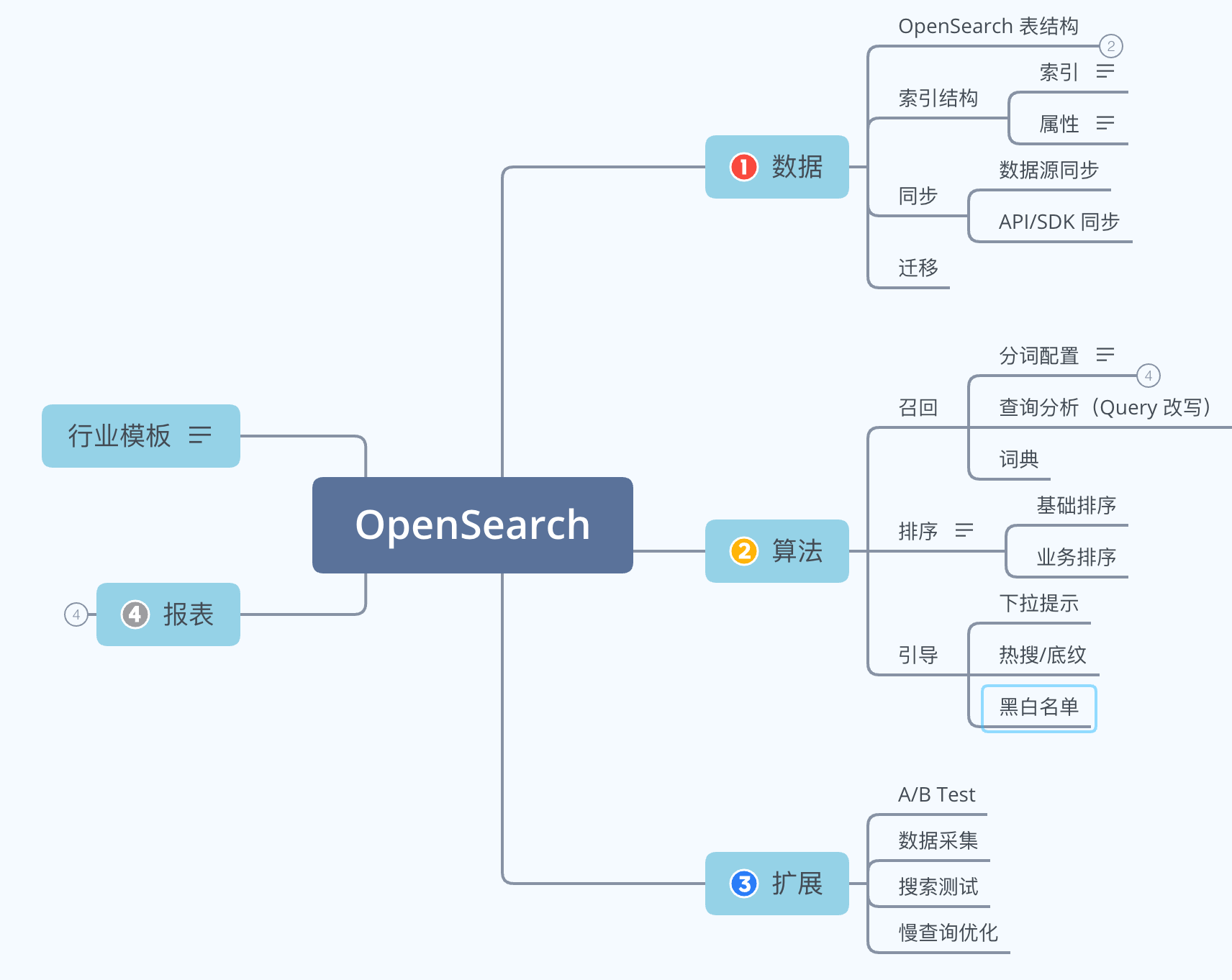
现行搜索逻辑
下拉提示
使用 OpenSearch 官方算法模型,针对标题(title)、分类(category lines)、品牌(brand) 属性抽取值并结合高频搜索词进行自动训练
搜索召回逻辑
- 索引名称:default
- 分词方式:中文-电商分析
- 字段:标题(title)、款号(sku)、品牌(brand)、全品类(category_lines)
- 词典:同义词、停顿词
- 索引名称:f_title
- 分词方式:模糊分析
- 字段:f_title
- 索引名称:fuzzy_brand
- 分词方式:模糊分析
- 字段:fuzzy_brand
- 索引名称:fuzzy_category_lines
- 分词方式:模糊分析
- 字段:fuzzy_category_lines
- 索引名称:sku
- 分词方式:模糊分析
- 字段:sku
搜索排序逻辑
基础排序:static_bm25 ,静态文本相关性,用于衡量query与文档的匹配度
业务排序:text_relevance,按照排序因子进行设置,如果简单表达式不能满足要求则需要升级实例并使用 cava 进行自定义排序。
举例来说,我想让搜索结果命中展示顺序为 title>brand>category_lines,那么我们配置的业务表达式为
text_relevance(f_title)*3 + text_relevance(fuzzy_brand)*2 + text_relevance(fuzzy_category_lines)此时搜索语句对应为
query=f_title:"运动鞋" OR fuzzy_brand:"运动鞋" OR fuzzy_cates:"运动鞋"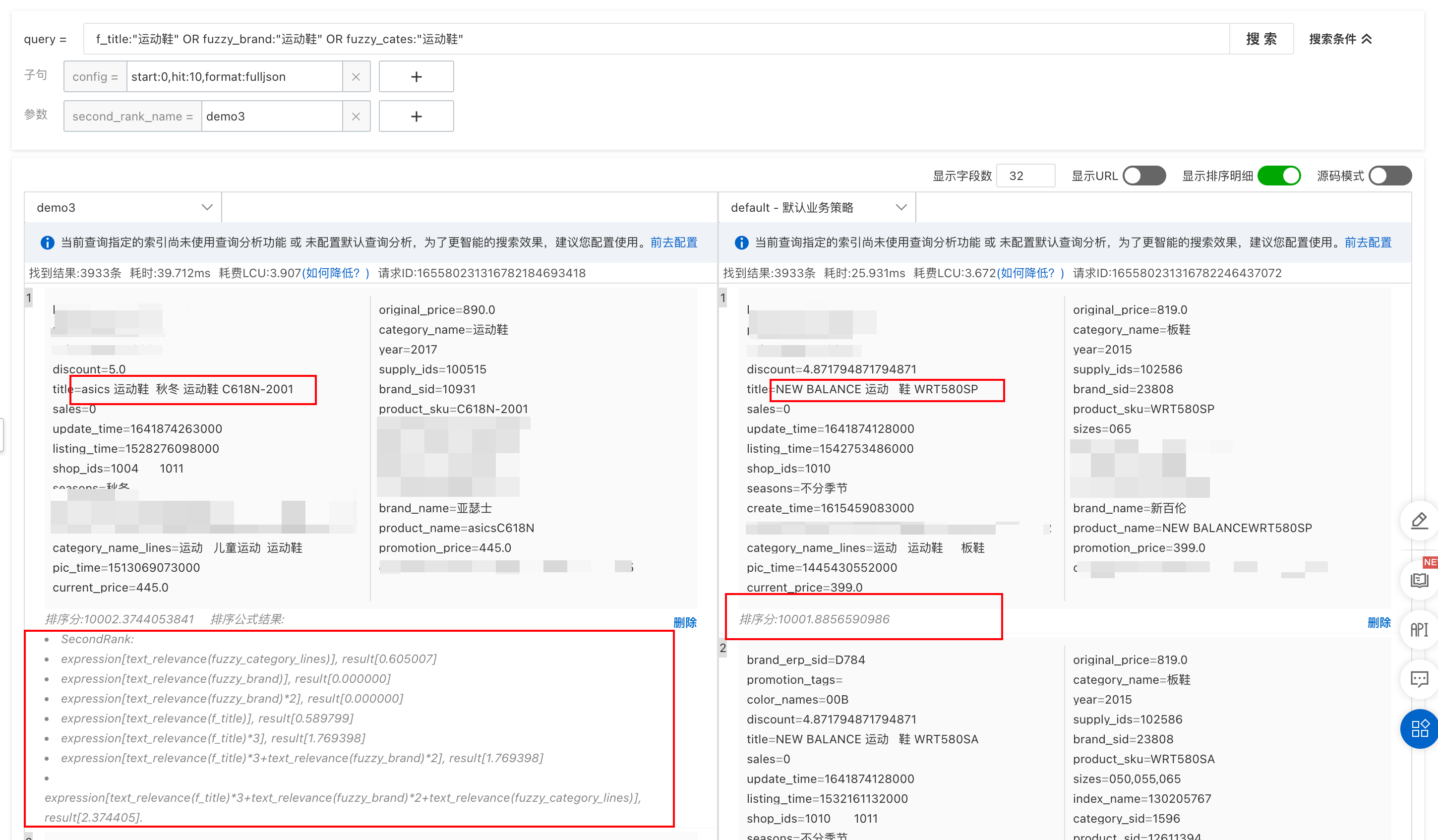
可以看出使用了 text_relevance 后会对三个索引进行加权算分。
数据采集
针对各端调用搜索时使用
- biz:来源,wechatshop、miniprogram、pc、ios、android
- userId:用户
- fromReqId:下拉提示点击进入搜索的 request id
当用户点击时记录
- 搜索的 requestId
- 商品 id
- 用户 id
主数据同步
我们采用的建立一个搜索宽表,存在 MySQL 中。
全量更新:每天凌晨 1 点钟进行同步,可手动触发,正向反向同步搜索宽表。
增量更新:针对主数据变更近实时更新,会通过监听主数据的 binlog 同步到搜索宽表中,OpenSearch 会自动将宽表中变化的数据同步到索引。
踩坑处理
模糊分析不够用怎么办?
对 SHORT_TEXT 的模糊分词不支持配置查询分析,如果出现 badcase 无法处理,那么可以增加一个 TEXT 的索引进行分析器配置,具体文章。
搜索关键词中有\特殊符号怎么办?
使用反斜杠进行转义,如搜索
H'S需要处理成H\'S进行搜索如何识别用户搜索的是款号?
因为款号这类属于精准搜素,最好是单独配置索引,默认程序并不知道用户输入的是款号还是关键词,那么需要定义什么是款号,这需要在商品系统中把在售商品款号查出来进行归类,比如我们定义的款号规则为纯数字或者数字+款号,那么当关键词匹配到了这个规则说明用户此时搜索即为款号。
总结
搜索核心离不开分词、相关性算分,OpenSearch 内置了大量的 分析器 以及相关性搜索实践
欢迎交流搜索相关问题 ahianzhang@gamil.com
- 原文作者:浮华生
- 原文链接:https://www.ahianzhang.com/post/summary20/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。